
Büyük Veri Nedir, Ne Değildir?
Geleneksel medyanın yeni medya teknolojileriyle birlikte sığmaya çalıştığı büyük medya arenasında bilginin ve verinin tek yönlü kaynaklardan toplanıp dağıtıldığı çağ yerini yavaş yavaş büyük veri çağına bıraktı. Bizlerse attığımız her adımın, yazdığımız her mesajın dijital bir iz bırakmaya başladığı bu dünyada, çoğu zaman büyük resim gibi büyük verinin de farkında bile değiliz.
“Mevcut bilgi sistemlerinin işlemekte güçlük çekeceği boyut ve karmaşıklıktaki verileri içeren kümelere big data denir.” çok kafa karıştırıcı görünürken, “Büyük veri analizi çalışma tablolarından veri tabanlarına sunuculardan toplanmış her türlü veriyi analiz edilecek hale getirmedir.” yetersiz bir tarif gibi durmaktadır. Bilgisayar mühendisi arkadaşım Serkan Şengönül’e birkaç üniversitede yaptığı “Big Data Journey” sunumundan esinlenerek hazırladığım bu yazıya ilham verdiği için kendisine teşekkürü bir borç bilirim.
Şengönül, big datayı anlaşılır kılmak adına veriyi pirinç taneleri üzerinden özetler:
Tek bir küçük pirinç tanesini byte olarak düşünelim.

Öyleyse kilobyte bir kap pirinç olacaktır.

Megabyte için 8 çuval pirinç dersek…

Gigabyte 3 tır hacminde pirince eşdeğer olacaktır.

1 terabyte’ı düşünebiliyor musunuz? Bu tam 2 konteyner gemisi hacminde pirinç demek!

Bilgisayarlarımızda kullandığımızdan biraz daha büyük verilere bakacak olursak… 1 petabyte Manhattan’ın üstünü örtebilecek boyutta olacaktır.

Exabyte ise batı yakasındaki tüm eyaletleri kaplayacak kadar büyük demektir.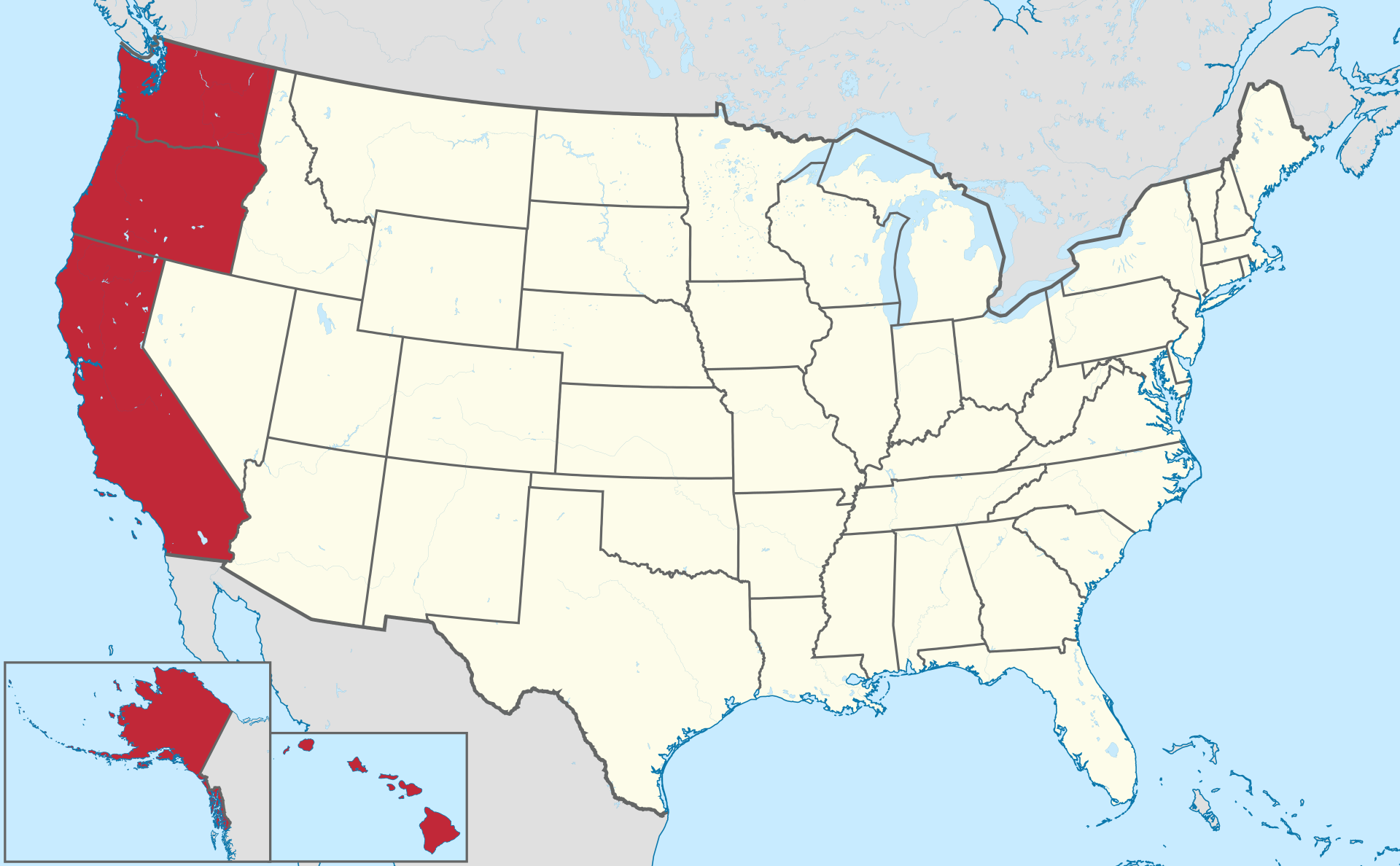
Başka veri tipi de mi varmış ya dediğinizi duyar gibiyim. Serkan’ı dinlerken ben demiştim çünkü. Zettabyte Pasifik Okyanusu’nu tamamen dolduracak kadar fazla pirinç tanesini ifade ediyor. Biraz sulu bir pilav olacak gibi sanki…

Aklımın büyüklüğünü bir türlü almadığı sonuncu veri boyutu tanımını ise yottabyte ile yapabiliriz. Yottabyte için dünya büyüklüğünde devasa bir pirinç topu yaratmamız gerekiyor!

Ne Uzak Ne de Yakın Gelecek
Verinin en küçük iki tipi olan byte ve kilobyte fazla karmaşık işlevsel özellikleri olmayan temel düzeydeki mekanizmalar için yeterli olurken, dizüstü bilgisayarlarda daha çok megabyte ve gigabyte ile işlem yapıyoruz. İnternet sistemini bu piramitte terabyte ve petabyte olarak düşünürsek, exabyte ve zettabyte için artık big data diyebilmemiz mümkün. Facebook, Yahoo, Amazon, Ebay, Google gibi büyük şirketlerin veri sistemleri bu kategori içinde yer alıyor. Peki yottabyte’ı big datanın da ötesinde “gelecek” olarak tarif etmemiz mümkün mü?
Sevgili Serkan’ın sunumunda büyük veriyi büyük veri yapan nitelikler arasında hacim, hız, çeşitlilik, doğrulama, değer gibi kategorilerin hepsinde gerekli özellikleri barındırması gerektiğini söylemesi üzerine, anlayamadığımız her şeye büyük veri deme yanılgısından kurtulmamız gerektiğini anlamaya başladım.

Peki neden gelişmekte olan şirketler dakikalar içerisinde bu kadar hızlı ve kolay veri akışı sağlayan teknolojinin algoritmik kollarına kendilerini bırakmıyor Çünkü veri tutmayı birçok durumda maliyetli ve külfetli bulan sistemler, çoğunlukla büyük veri analizinin gerçek anlamda nasıl veri manipülasyonuna dönüştürülebileceğini ve hedef kitleye en kısa zamanda doğrudan ulaşma şansı elde edilebileceğinin henüz farkında değiller.

Gündelik zevklerimizden, konuştuğumuz konularla ilgili karşımıza çıkan reklamlara kadar her şey tarafımızdan toplanan veriler sayesinde büyük analiz mekanizmaları içinde işlenip kişiselleştirilerek her gün bizlere yeniden sunuluyor.
Bu koskocaman veri dünyasının içinde nasıl küçük bir kum tanesi olduğumuzu yeniden hatırlamak adına bir Netflix belgeseli olan “The Great Hack” ve seçim kampanyalarında büyük veriyi kullanmak üzerine yazılan bir haberin linkini iliştirmek istiyorum. Bunların yanında sizleri de teknolojinin geldiği ve geleceği kırılma noktaları üzerine düşünmeye davet ediyorum.
Faydalı Linkler ve Kaynakça
- https://www.netflix.com/search?q=the%20great%20hack
- https://www.scmp.com/yp/learn/college-uni-life/university-programmes/article/3071524/how-data-analytics-helped-obama-win
- Big Data Journey/Serkan Şengönül, Sunum, 2022
Yorumunuzu Yayınlayın